Caching
缓存使您的应用程序即使在从网络加载数据、处理大量数据集或执行昂贵计算时也能保持高性能。
缓存的基本思想是存储昂贵函数调用的结果,并在再次出现相同输入时返回缓存的结果。这避免了用相同输入值重复执行函数。
在 Streamlit 中缓存函数,你需要为其应用缓存装饰器。你有两种选择:
st.cache_data 是推荐用于缓存返回数据的计算的方法。当您使用返回可序列化数据对象的函数(例如 str, int, float, DataFrame, dict, list)时,请使用 st.cache_data 。它在每次函数调用时都会创建数据的新副本,因此可以防止数据的修改和竞态条件。在大多数情况下, st.cache_data 的行为就是您想要的——所以如果您不确定,从 st.cache_data 开始使用并看看是否有效!
st.cache_resource 是推荐用于缓存全局资源,如机器学习模型或数据库连接的方法。当你的函数返回不可序列化的对象,且你不想多次加载时,使用 st.cache_resource 。它返回缓存的对象本身,该对象在所有重运行和会话中共享,无需复制或重复。如果你使用 st.cache_resource 缓存的对象发生变异,这种变异将在所有重运行和会话中存在。
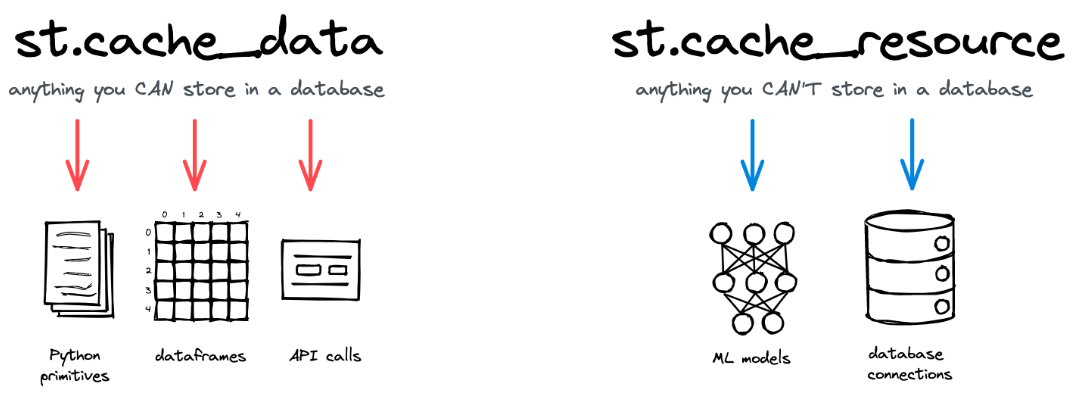
Deciding which caching decorator to use
上述部分展示了每种缓存装饰器的许多常见示例。但还有一些边缘情况,决定使用哪种缓存装饰器并不那么明显。最终,这一切都归结于“数据”和“资源”之间的区别:
数据是可序列化的对象(可以通过 pickle 转换为字节的对象),你可以轻松地将它们保存到磁盘。想象一下你通常会在数据库或文件系统中存储的所有类型 - 基本类型如 str、int 和 float,但也有数组、DataFrame、图像,或者这些类型的组合(列表、元组、字典等)。
资源是不可序列化的对象,通常你不会将它们保存到磁盘或数据库中。它们通常是更复杂、非永久性的对象,如数据库连接、ML 模型、文件句柄、线程等。
从列出的类型来看,很明显 Python 中的大多数对象都是“数据”。这也是为什么 st.cache_data 是几乎所有使用场景的正确命令的原因。 st.cache_resource 是一个较为罕见的命令,你只应在特定情况下使用它。
| Use case | Typical return types | Caching decorator |
|---|---|---|
| Reading a CSV file with pd.read_csv | pandas.DataFrame | st.cache_data |
| Reading a text file | str, list of str | st.cache_data |
| Transforming pandas dataframes | pandas.DataFrame, pandas.Series | st.cache_data |
| Computing with numpy arrays | numpy.ndarray | st.cache_data |
| Simple computations with basic types | str, int, float, … | st.cache_data |
| Querying a database | pandas.DataFrame | st.cache_data |
| Querying an API | pandas.DataFrame, str, dict | st.cache_data |
| Running an ML model (inference) | pandas.DataFrame, str, int, dict, list | st.cache_data |
| Creating or processing images | PIL.Image.Image, numpy.ndarray | st.cache_data |
| Creating charts | matplotlib.figure.Figure, plotly.graph_objects.Figure, altair.Chart | st.cache_data (but some libraries require st.cache_resource, since the chart object is not serializable – make sure not to mutate the chart after creation!) |
| Loading ML models | transformers.Pipeline, torch.nn.Module, tensorflow.keras.Model | st.cache_resource |
| Initializing database connections | pyodbc.Connection, sqlalchemy.engine.base.Engine, psycopg2.connection, mysql.connector.MySQLConnection, sqlite3.Connection | st.cache_resource |
| Opening persistent file handles | _io.TextIOWrapper | st.cache_resource |
| Opening persistent threads | threading.thread | st.cache_resource |
Controlling cache size and duration
如果您的应用运行时间长且不断缓存功能,可能会遇到两个问题: 1. 内存占用增加:长时间运行的应用程序可能会导致内存占用增加,因为缓存功能需要存储大量的数据。这可能会导致系统运行缓慢,甚至可能导致应用程序崩溃或系统性能下降。 2. 性能下降:频繁的缓存操作可能会增加应用程序的处理时间,特别是在处理大量数据或高并发请求时。这不仅会影响用户体验,还可能导致应用程序响应速度变慢。 为了解决这些问题,可以采取以下措施: - 定期清理缓存:设置缓存的有效期,过期的缓存数据会被自动清除,以释放内存空间。 - 优化缓存策略:根据数据的访问频率和重要性,合理分配缓存资源,避免不必要的缓存操作。 - 使用内存管理工具:监控应用的内存使用情况,及时发现并处理内存泄漏等问题,以提高应用的稳定性和性能。 通过这些方法,可以有效管理应用的缓存,避免资源浪费,提升用户体验
您可以使用 ttl 和 max_entries 这两个参数来解决这些问题,这两个参数对于缓存装饰器都可用。
The ttl (time-to-live) parameter
ttl 设置缓存函数的有效期。如果这个时间到了,你再次调用函数,应用将丢弃任何过时的、缓存的值,并重新运行函数。然后计算出的新值将被存储在缓存中。
这种行为对于防止过期数据(问题 2)和缓存变得过大(问题 1)很有用。尤其是在从数据库或 API 获取数据时,你应该始终设置 ttl ,以确保不使用过期数据。以下是一个示例
The max_entries parameter
Dealing with large data
正如我们所解释的,你应该使用 st.cache_data 缓存数据对象。但这对于极其庞大的数据,例如 DataFrame 或超过 1 亿行的数组,可能会很慢。这是因为 st.cache_data 的复制行为:在第一次运行时,它将返回值序列化为字节,并在后续运行时进行反序列化。这两个操作都需要时间。
如果你正在处理极其大量的数据,使用 st.cache_resource 可能是有意义的。它不会通过序列化/反序列化创建返回值的副本,并且几乎是即时的。
但请注意:对函数返回值的任何修改(例如从 DataFrame 中删除一列或在数组中设置一个值)会直接操作缓存中的对象。您必须确保这不会破坏您的数据或导致程序崩溃。请参阅下面的关于修改和并发问题的部分。